![]()
AI4HPC: AI-based Scalable Analytics for Improving Performance, Resilience, and Security of HPC Systems
What is AI4HPC?
This web application aims to demonstrate a supervised machine learning framework that can detect and
diagnose performance anomalies in HPC systems. A user can interact with the web application in two ways:
- Use sample telemetry data: The user can select from the sample telemetry data files provided in the web application. This option enables the user to quickly see the results of the framework.
- Upload your own data: The user can upload their own telemetry collected via Lightweight Distributed Metric Service.
Motivation
As data centers that serve many essential societal applications grow larger and become more complex, they
suffer more from performance variations caused by software bugs, shared resource contention (memory,
network, CPU, etc.), and hardware-related problems. These variations have become more prominent due to
limitations on power budgets as we move towards exascale systems. Unpredictable performance degrades the
energy and power efficiency of computer systems, resulting in lower quality-of-service for users, wasted
power, and higher operational costs.
Machine learning (ML) has been gaining popularity as a promising method to detect and diagnose anomalies in
large-scale computer systems. However, many of the proposed ML solutions are not publicly available to the
research community. Our team has developed a novel supervised ML framework that diagnoses previously
encountered anomalies in large-scale computer systems based on the performance telemetry data collected
during application runs. Our overarching goal is to determine the root causes of hard-to-debug anomalies in
computer systems in a heavily automated manner, thus reducing the delays, inefficiencies, and costs
resulting from performance problems. We evaluated our framework on production HPC systems and showed that it
outperforms current state-of-the-art anomaly diagnosis techniques, reaching up to a 0.97 F1-score.
Technical Details
As the first step in making our anomaly diagnosis frameworks widely accessible to the community, we have
developed AI4HPC, a web application that utilizes the Python Flask library. We have divided the overall
architecture into three blocks, and the following sections will provide detailed explanations of each.

A user can choose between two options. The first option is to use the sample data we provide. In this option, we don't train the model; instead, we utilize the pre-trained model that we have on the Flask server.

The second option allows users to upload their own datasets. We explain the details of each step in the figure below.
Offline Training and Deployment Architecture
- In the offline training and deployment stage, we perform feature extraction and feature selection, which are referenced as the Data Preprocessing Pipeline in the diagram, on the training dataset.
- Next, a Random Forest Classifier is trained on the training dataset using the selected features.
- Once the ML model is trained, it is saved as a .sav object in the Flask server.
A user can choose between two options. The first option is to use the sample data we provide. In this option, we don't train the model; instead, we utilize the pre-trained model that we have on the Flask server.
Option 1: Sample Data
- First, we extract the statistical features of the input data, and then select the features determined in the offline training and deployment stage.
- Next, we deploy the model on the Flask server and provide anomaly diagnosis results.
The second option allows users to upload their own datasets. We explain the details of each step in the figure below.
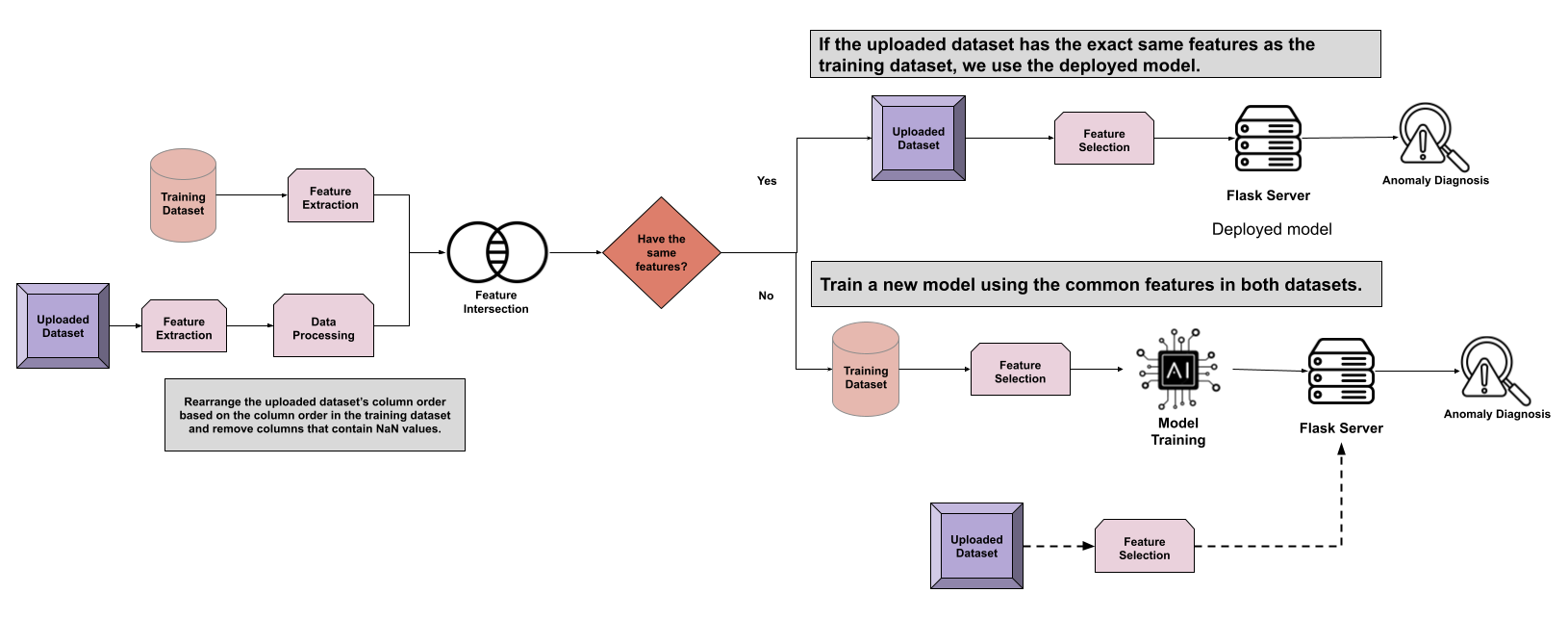
Option 2: Custom Upload
- First, we perform feature extraction on both datasets: the training dataset and the uploaded dataset.
- We perform the following data processing steps on the uploaded dataset:
- Rearrange the column order
- Drop the columns with NaN values
- Next, we find the intersection between the columns of the two datasets. Depending on the outcome of the intersection, there may be two different paths:
- If the training dataset has the exact same features as the uploaded dataset:
- We perform feature selection on the feature-extracted version of the uploaded dataset.
- Then, we use the deployed model stored in the Flask server to perform an anomaly diagnosis.
- Else, we train a model using the common features in both datasets:
- First, we perform feature selection on the feature-extracted version of the training dataset .
- Then, a new model is trained, and the newly trained model will be stored in the Flask server.
- As a final step, we select the same features that were used during training from the uploaded dataset and make predictions using the new model.